SEO (Search Engine Optimization, eller sökmotoroptimering på svenska) är aktiviteter som syftar till att öka en hemsidas organiska synlighet i sökmotorernas resultat. Målet med SEO är ofta att få in fler besökare till en hemsida, men det kan också vara att få in rätt besökare till sin sajt. Att sökordsoptimera din hemsida går ut på att du gör det lätt för besökare och sökmotorer att förstå vad sidan handlar om samt att koppla dess innehåll till relevanta sökord och sökfraser. När besökaren är nöjd, är också sökmotorerna det, vilket visar sig genom högre ranking i de organiska sökresultaten.
Här tar vi ett första kliv in i en introduktion till sökmotoroptimering. Du bör redan nu veta att SEO är tidskrävande och för att lyckas behöver du ha en genomtänkt strategi. Du kommer aldrig att få full effekt vid en engångsinsats – för bästa resultat krävs ett löpande arbete.
Varför är SEO viktigt?
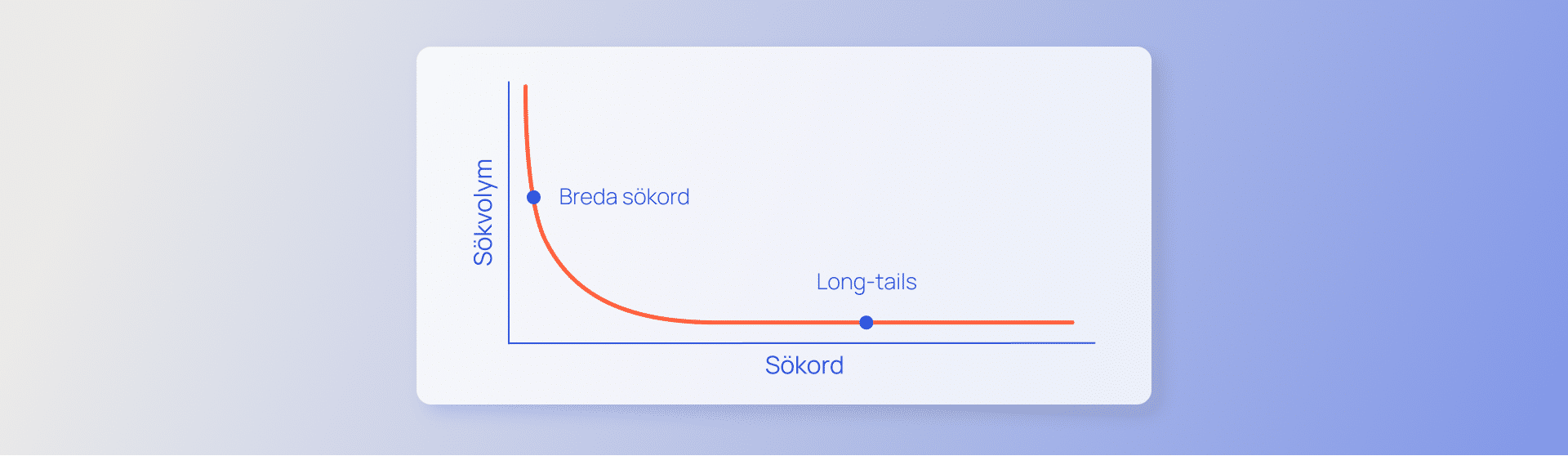
SEO är en viktig del i marknadsföringen, särskilt eftersom Google har seglat upp och blivit världens största marknadsplats. Statistik visar att det under 2021 gjordes 55 miljoner sökningar på Google varje dag, enbart i Sverige. Det är 55 miljoner chanser till exponering för personer som letar efter något.
För det resultat som rankar på första position är klickfrekvensen ungefär 30 %. Det innebär att 30 % av dem som har sett det första organiska resultatet också väljer att klicka på det. Klickfrekvensen halveras sedan för varje placering efter det, vilket innebär att den redan på den femte placeringen är nere under 3 %. Väldigt få tar sig till sida 2, ännu färre till sida 3. Därför är det viktigt att arbeta med SEO. Det kan liknas vid att bära reflex i mörkret – syns du inte, finns du inte.
7 fördelar med sökoptimering
Det finns mycket att vinna på att arbeta med sökoptimering. Här är sju fördelar som kan ge din verksamhet en rejäl boost.
-
Ökad organisk synlighet
-
Mer trafik till hemsidan
-
Relevanta besökare
-
Ökad försäljning/fler leads
-
Bättre användarupplevelse
-
Högre kundförtroende
-
Starkare varumärke
Hur fungerar sökmotoroptimering?
Varje sökmotor har en så kallad sökrobot som crawlar alla sidor som finns ute på internet. Genom att ”klättra” via både extern- och internlänkning kan de samla in så mycket information som möjligt. De sparar sedan denna information i sökmotorns index – det som bygger upp hela databasen ur vilken resultaten på Google och andra sökmotorer hämtas. Varje sökmotor har sitt eget index som matas med en algoritm som matchar datan med sökord. Sökmotoroptimering handlar om att göra din hemsida synlig för sökrobotarna och du säkerställer att robotarna faktiskt kan crawla på din sida.
Sökordsoptimera din hemsida för Google och för användarna
Innan du sätter dig in i SEO och förstår hur det fungerar känns det troligtvis krångligt och abstrakt. Vem är det egentligen du optimerar för? Svaret är enkelt: du ska sökordsoptimera din hemsida för besökarna, och därmed för sökmotorerna.
Sökmotorernas index
Varje sökmotor har en crawler, en så kallad sökrobot (Googles heter till exempel Googlebot). Denna crawlar alla hemsidor på internet och hämtar information för att lagra i sitt index och göra sidorna sökbara på exempelvis Google – det är detta som menas med indexering. För att indexera sidor navigerar robotarna via länkar som vägleder dem från en sida till en annan.
Det som visas i sökresultaten är inhämtat från detta index, filtrerat genom sökmotorernas algoritmer som försöker matcha olika sökord med de mest relevanta sidorna. Att sökordsoptimera handlar i stor utsträckning om att synliggöra en hemsida och dess innehåll för sökrobotarna. Om det finns en blockering som sökrobotarna inte kan ta sig förbi, kommer sidan inte heller att crawlas och därmed inte heller kunna synas i sökresultaten.
Även om Googles sökrobotar är smarta, behöver vi hjälpa dem på traven för att de ska hitta till sidan. Här är det viktigt att du gör ett bra arbete med att sökordsoptimera din hemsida för att sökmotorerna ska kunna tolka innehållet. Det finns flera olika rankingfaktorer som alla spelar olika roller.
Användarnas beteende
Genom att iaktta användarnas beteende kan sökmotorerna få hjälp att avgöra hur relevant innehållet på en sida är för användaren. Föreställ dig följande scenario:
En användare gör en sökning på Google och väljer att interagera med det första organiska resultatet i SERP:en. Besöket på sidan blir kortvarigt då hen inte hittar det hen söker tillräckligt snabbt eller tidigt på sidan. Användaren går då tillbaka till Google, och vidare in på nästa sida i sökresultatet. Där inne tillbringar hen längre tid och återvänder sen inte tillbaka till Google.
Detta sänder tydliga signaler till Google om att innehållet på sidan som hade den högsta rankingen inte var tillräcklig för att tillfredsställa besökaren. Däremot var innehållet på nästa sida så bra att besökaren kände sig nöjd med resultatet. Den här typen av användardata hjälper sökmotorerna att presentera de mest relevanta sidorna för sina användare.
Arbeta med SEO på flera fronter
Vi kommer att snudda vid några av dessa senare i artikeln, men det vi framför allt kan se är att du måste arbeta med SEO på flera fronter för att lyckas. Inom SEO pratar man ofta om två olika delar: on page och off page. Dessa angriper sökmotoroptimering på något olika sätt; on page syftar till interna faktorer såsom innehåll och HTML-kod, medan off page fokuserar på externa faktorer såsom den auktoritativa ställningen online och länkar från andra hemsidor.
On page
All on page SEO görs direkt på hemsidan. Detta inkluderar egentligen allt som finns på sidan såsom innehåll i form av text, rubriker och bilder, men även URL-struktur och källkod. Det handlar till lika stor del om att få bättre ranking i det organiska sökresultat som det gör om att förbättra upplevelsen för den besökare som kommer in via Google eller andra sökmotorer. Det hela kan kokas ner till att man behöver uppfylla besökarens sökintention genom att tillhandahåll relevant innehåll.
Förr var det lätt att förstå sig på sökmotorernas algoritmer – då handlade SEO om att använda ett sökord så mycket som möjligt, och alla medel var tillåtna. Kanske minns du en tid då det gömde sig vit text på vit bakgrund? Du kunde med säkerhet sälla dig till en frustrerad användarskara som inte hittade vad de sökte, vilket så klart inte spelade sökmotorerna i händerna. Med tiden har algoritmen förändrats till det bättre och nu är det istället de mest relevanta sidorna som rankar högst på Google – det vill säga det resultat som bäst träffar sökintentionen. Bland annat.
Off page
Med off page SEO avses all typ av optimering som görs utanför den egna webbplatsen. Det handlar först och främst om så kallade backlinks, det vill säga länkar som kommer från andra webbplatser, men också från sociala medier och andra digitala plattformar.
När SEO var nytt utnyttjade många aktörer backlinks på samma sätt som de gjorde med användningen av sökord. Länkar producerades i enorma mängder, men saknade ofta kvalitet. Resonemanget bakom backlinks är att en sida som många refererar till (länkar till) måste ha hög trovärdighet. Dessa belönades med en hög auktoritativ status och premierades därmed också i sökresultaten, trots att den typen av länkar egentligen är att betrakta som spam. I dag tar sökmotorernas algoritmer större hänsyn till kvaliteten och relevansen bakom backlinks. Om detta saknas, ja då betraktas de faktiskt numera som spam.
SEO på lokal nivå
Topplaceringarna domineras ofta av stora aktörer, men man behöver inte vara stor för att synas. Det handlar om att förstå sökmotorernas algoritmer och anpassa sig därefter. Lokal SEO syftar till att ge ökad synlighet för geografiskt avgränsade sökningar. För ett företag med verksamhet på flera orter är det alltså möjligt att öka synligheten genom att arbeta med sökoptimering som riktar in sig på specifika geografiska områden.
Hur får man sin hemsida att synas på Google med hjälp av SEO
SEO är det givna svaret på hur man får sin hemsida att synas på Google. Det är däremot inte så enkelt som det kan verka. Låt oss snudda lite vid några viktiga rankingfaktorer att ta hänsyn till när du ska sökordsoptimera din hemsida.
Metadata
Metadata syftar på två meta-element i sidans HTML-kod; sidtitel och metabeskrivning. Detta är den första kontakten som Google-användaren har med din sida då detta är vad som visas i sökresultatet. Här är det viktigt att fånga användarens intresse.
Rubrikstruktur
I HTML-koden finns olika typer av rubriktaggar (H1, H2, H3 etc.) som först och främst ger sökmotorerna en förståelse över sidans struktur, men också en bra överblick av sidans innehåll även för besökaren.
URL
URL:en fyller en viktig funktion då den kan visa vad en sida handlar om – redan innan man äntrar sidan. Genom att skapa en URL-struktur för SEO går det att hjälpa sökmotorerna på traven när det kommer till att tolka innehållet på en sida.
Innehåll
Innehållet på en sida är bland de viktigaste rankingfaktorerna inom SEO. Det är här som du besvarar sökintentionen och kan servera besökaren det hen vill ha. För att hjälpa sökmotorerna att förstå att ditt innehåll är relevant är det viktigt att skriva bra SEO-text genom användning av sökord. Däremot får det inte kännas onaturligt för besökaren – varken Google eller dess användare är förtjusta i spammigt innehåll.
Bilder
Utöver rubriker och brödtext kan bilderna som finns på en hemsida påverka dess möjlighet att ranka i det organiska sökresultatet. Det finns flera sätt att optimera bilder för webben på; bildoptimering handlar om att göra det enklare för sökmotorerna att tolka innehållet i bilderna. Valet av bild, dess format och storlek samt alt-text är några av de faktorer som påverkar hur din sida presterar.
Hur får man sin hemsida att synas på Google med hjälp av SEO
SEO är det givna svaret på hur man får sin hemsida att synas på Google. Det är däremot inte så enkelt som det kan verka. Låt oss snudda lite vid några viktiga rankingfaktorer inom sökmotoroptimering.
Metadata
Metadata syftar på två meta-element i sidans HTML-kod; sidtitel och metabeskrivning. Detta är den första kontakten som Google-användaren har med din sida då detta är vad som visas i sökresultatet. Här är det viktigt att fånga användarens intresse.
Rubrikstruktur
I HTML-koden finns olika typer av rubriktaggar (H1, H2, H3 etc.) som först och främst ger sökmotorerna en förståelse över sidans struktur, men också en bra överblick av sidans innehåll även för besökaren.
URL
URL:en fyller en viktig funktion då den kan visa vad en sida handlar om – redan innan man äntrar sidan. Genom att skapa en URL-struktur för SEO går det att hjälpa sökmotorerna på traven när det kommer till att tolka innehållet på en sida.
Innehåll
Innehållet på en sida är bland de viktigaste rankingfaktorerna inom SEO. Det är här som du besvarar sökintentionen och kan servera besökaren det hen vill ha. För att hjälpa sökmotorerna att förstå att ditt innehåll är relevant är det viktigt att skriva bra SEO-text genom användning av sökord. Däremot får det inte kännas onaturligt för besökaren – varken Google eller dess användare är förtjusta i spammigt innehåll.
Bilder
Utöver rubriker och brödtext kan bilderna som finns på en hemsida påverka dess möjlighet att ranka i det organiska sökresultatet. Det finns flera sätt att optimera bilder för webben på; bildoptimering handlar om att göra det enklare för sökmotorerna att tolka innehållet i bilderna. Valet av bild, dess format och storlek samt alt-text är några av de faktorer som påverkar hur din sida presterar.
Varför syns inte min hemsida på Google?
Det finns flera anledningar till att din hemsida kanske inte syns på Google.
Webbplatsen är inte indexerad
För att din webbplats ska kunna visas i sökresultaten måste den först indexeras av Google. Detta innebär att Googles sökmotorrobotar måste kunna hitta och läsa din webbplats. Om du nyligen har skapat din webbplats kan det ta några dagar innan den indexeras.
Du kan kontrollera om din webbplats är indexerad genom att söka efter den i Google Search Console.
Hemsidan har inte tillräckligt med innehåll
Google vill visa relevanta och användbara resultat för användarnas sökningar. Om din hemsida inte har tillräckligt med innehåll är det osannolikt att den kommer rankas högt i sökresultaten.
Se till att ditt innehåll är relevant och användbart för dina målgrupper.
Du saknar relevanta länkar
Länkar från andra webbplatser är ett viktigt tecken på att din webbplats är relevant och användbar. Om din webbplats inte har tillräckligt med relevanta länkar kan den inte rankas högt i sökresultaten.
Det är här som off-page-arbetet kommer in i bilden. Se till att skapa innehåll som är värt att länka till och försök få ut länkar på andra relevanta sidor.
Det finns tekniska problem
Tekniska problem som exempelvis fel på webbservern eller otydliga URL-adresser, kan göra det svårt för Googles sökrobotar att hitta och indexera din webbplats.
Kom igång och få hjälp med sökmotoroptimering
Vill du lära dig mer om SEO? Ta del av våra SEO-tips för att komma igång med sökmotoroptimering. Vi ger dig tips och råd kring några av de viktigaste faktorerna för att lyckas med den organiska synligheten av din webbplats.
Om du hellre vill få hjälp med sökmotoroptimering till någon med specialistkunskaper är du välkommen att ta kontakt med oss på Noor Digital – du får då ett team av specialister som jobbar dedikerat med alla områden inom sökmotoroptimering på din hemsida.
Stockholm
Många av våra kunder har sina huvudkontor här – för oss är det en självklarhet att finnas nära dem som behöver vår hjälp med SEO i Stockholm.
Göteborg
Att jobba med SEO i Göteborg är lika självklart som att solen alltid går ner bortanför hamninloppet. Här omges vi av andra företag inom tech.
Umeå
Umeå är vår nordligaste hubb. Precis som Umeälven sträcker sig från Norge till Östersjön erbjuder vi SEO i Umeå och resten av norra Sverige.
Malmö
Malmö är på många sätt Sveriges port till resten av kontinenten. Att jobba med SEO i Malmö är den metaforiska porten till våra europeiska kunder.